Python pandasにおける~(チルダ)の使用例
~(チルダ)は、NOT演算子として使います。本記事では、pandasにて次の2つの使用例を示します。
使用例1:指定した列に対して、指定した要素以外の行データを抽出する
使用例2:df.duplicated()と組み合わせることで、重複要素がある行データを除外する
■使用例1:指定列に対して、指定した要素以外の行データを抽出する
まず、上記のpandasデータフレームは次の通りです。

上記を実行すると、下記のようにB列に対してX以外の行データを抽出します。
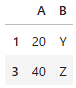
■使用例2:重複要素がある行データを除外する
上記は次のような重複のあるデータフレームです。
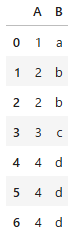
上記のように、df.duplicated() は重複している行を True、最初の出現を False とするブール配列を返します。
このため、次のように~(チルダ)を利用することで重複を除外することができます。

下表はその他一覧です。
| 操作 | コード | 残るデータ |
| 最初の出現を残す | df[~df.duplicated()] | 重複の最初の1つだけ |
| 最後の出現を残す | df[~df.duplicated(keep="last")] | 重複の最後の1つだけ |
| 重複データを完全に削除 | df[~df.duplicated(keep=False)] | 重複がすべて消える |
■指定した列に対して重複を削除する場合の例
下表は類似操作の一覧です。
| 操作 | コード | 残るデータ |
|
特定の列で重複を削除 (最初を残す) |
df[~df.duplicated(subset=["列名"])] | 最初の出現のみ残る |
|
特定の列で重複を削除 (最後を残す) |
df[~df.duplicated(subset=["列名"], keep="last")] | 最後の出現のみ残る |
| 特定の列で完全に重複を除外 | df[~df.duplicated(subset=["列名"], keep=False)] | 重複がすべて消える |
| 複数列で重複をチェック | df[~df.duplicated(subset=["列1", "列2"])] | 指定した列の組み合わせが重複する場合に除外 |
以上
<広告>
リンク
リンク
リンク