はじめに
Llama-3(ラマ)モデルはMeta社のオープンソースのLLM(大規模言語モデル)です。これを元に日本語での精度を向上させたモデルがいくつか公開されています。無料で利用できます。
本記事では、このLlama-3モデル(派生モデル)をローカルPCでChatGPTのように質問に対して応答するようなpythonの雛形コードを紹介します。使用するライブラリは「llama-cpp-python」「huggingface」です。LLMモデルの拡張子は「.gguf」です。
例題として使用させて頂いたLLMモデルは、https://huggingface.co/elyza/Llama-3-ELYZA-JP-8B-GGUF です。CPUでも動作するほど、軽くて速いです。但し、精度はそれなりです。逆に、高精度と思われるモデルはこちらです。https://huggingface.co/mmnga/Llama-3.1-70B-Japanese-Instruct-2407-gguf/tree/main 但し、動作は激重です(ビデオメモリが多いグラフィックボードが必要と思います。私が使用しているのはGeForece3060(VRAM12G)でも実用に耐えない)。
使用するPythonライブラリのインストール
Llama-3モデルを使用するために、以下の2つのPythonライブラリをインストールします。llama-cpp-pythonはLlamaモデルの実行に使用し、huggingfaceはモデルのダウンロードにて必要となります。
モデルの準備と実行
次に、Llama-3モデルを使って実際にチャットボットを動作させるPythonコードを紹介します。このコードは、指定したフォルダにモデルが存在しない場合、Hugging Faceのリポジトリから自動的にダウンロードします。すでに存在する場合はダウンロードで上書きするようなことはなく、それを読み込みます。
ちなみに、本コードには他のLLMモデルについても、リポジトリとモデルファイル名をコメントアウトで載せていますので、検証したい人は試してみてください。
コードの解説
-
ライブラリのインポートとモデルの設定
Llamaクラスを使用して、指定したディレクトリ内のモデルをロードします。repo_idにはモデルのリポジトリIDを指定し、filenameにはモデルのファイル名を指定します。 -
チャット生成関数
chat_bot_func関数は、指定したメッセージに対してLlamaモデルを使用して応答を生成します。messagesリストには、システムとユーザーの両方のメッセージが含まれ、これに基づいて応答が生成されます。stream=Trueにより、逐次応答が得られます。 -
応答の表示
forループ内で応答をリアルタイムに表示するようになっています。最後にfinishedと表示して、応答の終了を明確にします。
上記のコードを実行して得られた回答の結果(正しくない)
以下は、pandasを使用して、A列の要素グループ別に、B列とC列のそれぞれの平均値と合計値を算出して、新規データフレームを作成する方法です。 ```
``` 上記のコードでは、A列の要素グループ別に、B列の平均値とC列の合計値を算出しています。`groupby`関数を使用して、A列の要素グループに分類し、`agg`関数を使用して、各グループのB列の平均値とC列の合計値を算出しています。`reset_index`関数を使用して、グループ化されたインデックスを復元しています。
以上の方法により、Llama-3モデルを使用して、ローカルPC上でChatGPTのような会話エージェントを簡単に実現できます。しかし、AIによって得られた内容が、本当に正しいかは注意してください。精度と速度はモデルによって全く異なります(それはトレードオフの関係にあります)。
以上
#################################
(参考)以下では、上記で生成されたコードの間違いの内容についてと、正しいコードについて記載しました(ChatGPT無料版による回答です)。
上記の回答コードの問題点
生成されたコードは一見正しく見えますが、いくつかの重要な問題点があります。
-
要求と結果の不一致:
- 質問では「B列とC列のそれぞれの平均値と合計値」を算出したいとしていますが、生成されたコードでは、B列の平均値とC列の合計値しか計算していません(下図)。つまり、B列の合計値とC列の平均値が計算されておらず、要求された内容と一致していません。
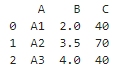
-
agg関数の誤用:agg関数は複数の集約関数を適用するために使用できますが、コードではB列にmeanのみ、C列にsumのみが適用されています。複数の集約関数を適用するためには、以下のように辞書内にリスト形式で集約関数を指定する必要があります。
- 結果の解釈の難しさ:
-
- 上記の修正後のコードで得られるデータフレームは、多重インデックスとなり、初心者にとっては解釈が難しい場合があります。例えば、
reset_indexだけでは不十分で、列名を平坦化する処理が必要になることが多いです。
- 上記の修正後のコードで得られるデータフレームは、多重インデックスとなり、初心者にとっては解釈が難しい場合があります。例えば、
正しいアプローチ
groupbyで指定された列に対し、複数の集約関数を適用したデータフレームを得ることができます。列名のフラット化により、結果の解釈が容易になります。下図が、上記コードによる結果であり、質問に対する正解です。
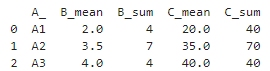
<広告>