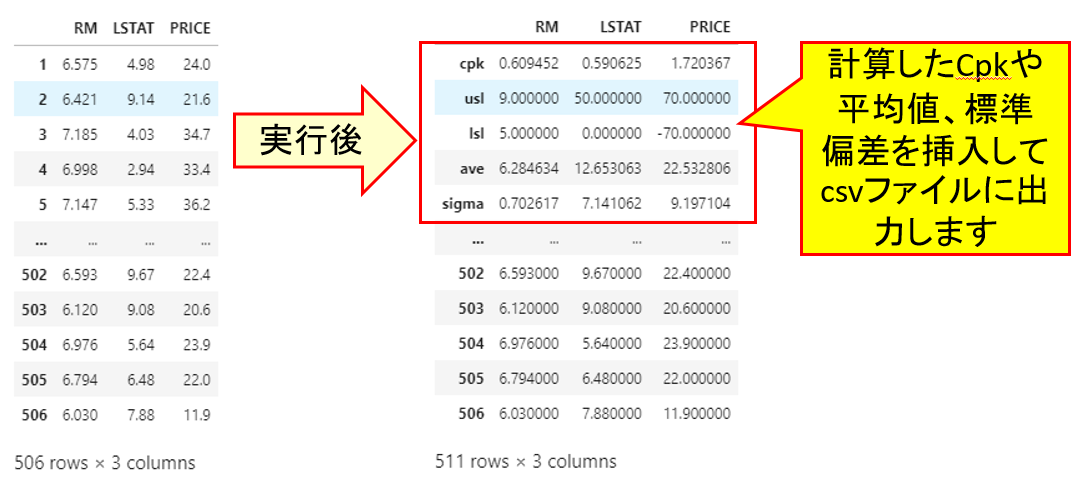
本記事では、csvファイルから各列のCpk(cpu, cplの小さい方)を計算して、csvファイルに出力する雛形コードを載せました。
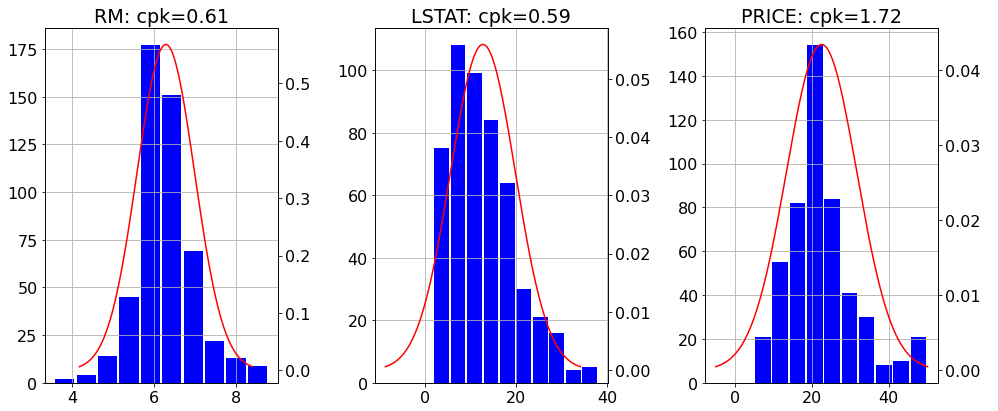
また、下図のようにヒストグラムも作成します。
使用した例題のcsvデータの作成方法は、次のリンク先を参照下さい。https://hk29.hatenablog.jp/entry/2019/12/10/201705
■本プログラム
import pandas as pd
import numpy as np
from matplotlib import pyplot as plt
plt.rcParams['font.size'] = 16
file_path = 'boston_XYdata.csv'
df = pd.read_csv(file_path)
df.index = np.arange(1, len(df) + 1)
df
DF = df[['RM', 'LSTAT', 'PRICE']]
DF.hist()
plt.tight_layout()
DF
def cpk_func(i, col, df_col, lsl, usl):
ave = df_col.mean()
sigma = np.std(df_col.values, ddof=1)
x = np.linspace(ave - 3 * sigma, ave + 3 * sigma, num = 1000)
y = np.exp(-(x - ave) ** 2 / (2 * sigma ** 2)) / (np.sqrt(2 * np.pi) * sigma)
cpu = (usl - ave) / (3 * sigma)
cpl = (ave - lsl) / (3 * sigma)
cpk = min(cpu, cpl)
ax = fig.add_subplot(1, len(DF.columns), i, title = col + ": cpk={:.2f}".format(cpk))
ax.hist(df_col.values, bins = 10, density=False, color='b', rwidth=0.9)
ax2 = ax.twinx()
ax2.plot(x, y, c='r')
ax.grid()
plt.tight_layout()
return ave, sigma, cpk
judge_list = [(5, 9), (0, 50), (-70, 70)]
ave_list = []
sigma_list = []
cpk_list = []
lower_judge_list = []
upper_judge_list = []
fig = plt.figure(figsize = (14, 6))
for i, (col, (lower, upper)) in enumerate(zip(DF.columns, judge_list), start=1):
my_ave, my_sigma, my_cpk = cpk_func(i, col, DF[col], lower, upper)
ave_list.append(my_ave)
sigma_list.append(my_sigma)
cpk_list.append(my_cpk)
lower_judge_list.append(lower)
upper_judge_list.append(upper)
cpk_list
def df_insert_func(df, index, value):
df1 = df.iloc[:index].append(pd.Series(value, index=df.columns), ignore_index=True)
df2 = df.iloc[index:]
df_concat = pd.concat((df1, df2)).reset_index(drop=True)
return df_concat
new_df = df_insert_func(DF, 0, sigma_list)
new_df = df_insert_func(new_df, 0, ave_list)
new_df = df_insert_func(new_df, 0, lower_judge_list)
new_df = df_insert_func(new_df, 0, upper_judge_list)
new_df = df_insert_func(new_df, 0, cpk_list)
new_df
row_list = DF.index.to_list()
new_index_list = ['cpk', 'usl', 'lsl', 'ave', 'sigma'] + row_list
new_df.set_axis(new_index_list, axis = 'index', inplace = True)
new_df.to_csv('new_' + file_path)
new_df
以上
<広告>
リンク