本記事では下図の凡例(legend)のRMのようにカテゴリ変数を指定数に分割して作成する。またそれを散布図にする雛形コードを載せました。
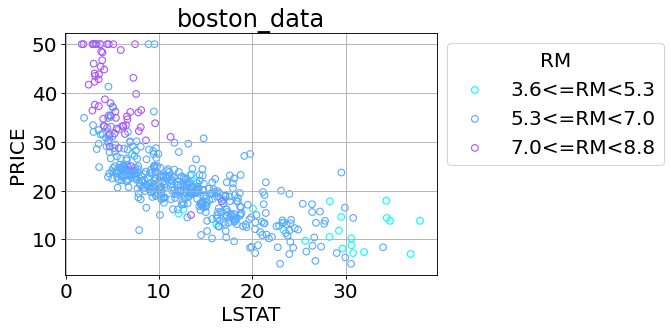
下図中にある列名「RM」のデータから、列名「label」というカテゴリ変数を作成します。それを上図のようにカテゴリ別に色を変えてプロットします。

■本プログラム
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import matplotlib.cm as cm
plt.rcParams['font.size'] = 18
df = pd.read_csv('boston_XYdata.csv')
df
legend_name = 'RM'
legend_list = df[legend_name].tolist()
print(legend_list)
data_min = min(legend_list)
data_max = max(legend_list)
print(data_min, data_max)
n_split = 3
data_delta = (data_max - data_min) / n_split
data_delta
x1_list = list(np.arange(data_min, data_max + 0.1, data_delta))
print(len(x1_list))
x1_list
n = 1
x2_list = x1_list[n:] + x1_list[:n]
print(x2_list)
x1_list.pop()
x2_list.pop()
print(x1_list, x2_list)
range_list = []
for x1, x2 in zip(x1_list, x2_list):
range_list.append([x1, x2])
print(len(range_list))
range_list
df_list = []
for _ in range_list:
my_min, my_max = _
df_buf = df[(df[legend_name] >= my_min) & (df[legend_name] < my_max)]
df_buf['label'] = '{0:.1f}'.format(my_min) + '<=' + legend_name + '<' + '{0:.1f}'.format(my_max)
df_list.append(df_buf)
DF = pd.concat(df_list)
DF
x_name = 'LSTAT'
y_name = 'PRICE'
label = 'label'
title = 'boston_data'
fig = plt.figure(dpi=80, figsize=(6,4))
handle_list = []
for i, legend in enumerate(DF[label].unique()):
print(i, legend)
plt.scatter(DF.loc[DF[label] == legend, x_name],
DF.loc[DF[label] == legend, y_name],
facecolor = 'None',
edgecolors = cm.cool(i / len(DF[label].unique())),
label = legend)
plt.legend(bbox_to_anchor = (1, 1), title = legend_name)
plt.xlabel(x_name)
plt.ylabel(y_name)
plt.title(title)
'''
x_min = 0
x_max = 20
y_spec = 150
'''
plt.grid()
plt.tick_params()
plt.show()
以上
<広告>
リンク