'22/05/03更新:ヒストグラムにしたデータを度数分布表へcsvに出力するコードを追記しました。
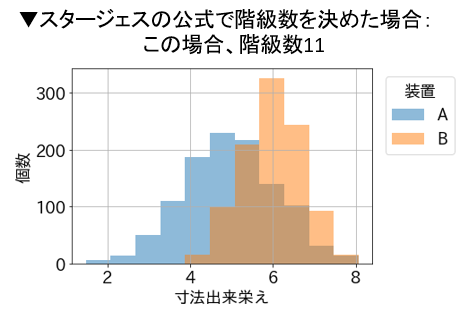
本記事では、下図のように2つのデータを重ね合わせる雛形コードを載せました。半透明で表示することで、それぞれの分布が見易くなります。
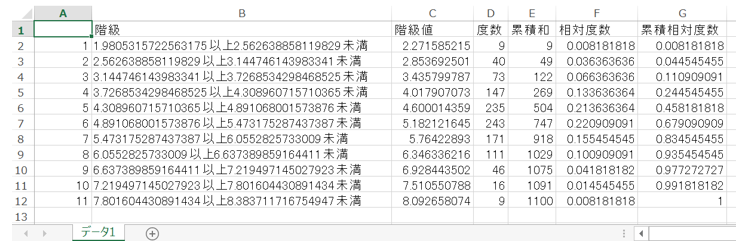
さらに、下図のように度数分布表をcsvファイルへ出力する仕様です。
次のように、階級数は引数binsで指定できます。そして、引数rangeを指定することで2つデータ群の階級幅を揃えることができます。
plt.hist(data, alpha = 0.5, bins = my_class_size, range = (my_min, my_max), label = 'A')
■本プログラム
import numpy as np
import pandas as pd
import math
import matplotlib.pyplot as plt
import japanize_matplotlib
plt.rcParams['font.size'] = 18
data1_np = np.random.normal(
loc = 5,
scale = 1.1,
size = 1100,
)
min1 = min(data1_np)
max1 = max(data1_np)
data1_size = len(data1_np)
print(min1, max1, data1_size)
data2_np = np.random.normal(
loc = 6,
scale = 0.7,
size = 1000,
)
min2 = min(data2_np)
max2 = max(data2_np)
data2_size = len(data2_np)
print(min2, max2, data2_size)
if min1 <= min2:
my_min = min1
else:
my_min = min2
if max1 >= max2:
my_max = max1
else:
my_max = max2
print(my_min, my_max)
if data1_size >= data2_size:
N = data1_size
else:
N = data2_size
print(N)
my_class_size = int(1 + math.log2(N))
print('my_class_size', my_class_size)
my_class_width = (my_max - my_min) / my_class_size
print('my_class_width', my_class_width)
x_name = '寸法出来栄え'
y_name = '個数'
legend_name = '装置'
plt.hist(data1_np, alpha = 0.5, bins = my_class_size, range = (my_min, my_max), label = 'A')
plt.hist(data2_np, alpha = 0.5, bins = my_class_size, range = (my_min, my_max), label = 'B')
plt.xlabel(x_name)
plt.ylabel(y_name)
plt.legend(bbox_to_anchor = (1.3, 1), title = legend_name)
plt.grid()
plt.show()
def extract_hist_data_func(DATA, CLASS_SIZE, MIN, MAX, FILE_NAME):
class_width = (MAX - MIN) / CLASS_SIZE
bins = np.arange(MIN, MAX + class_width, class_width)
class_value = (bins[1:] + bins[:-1]) / 2
hist = np.histogram(DATA, bins)[0]
class_name = [f'{bins[i]}以上{bins[i+1]}未満' for i in range(hist.size)]
cumsum = hist.cumsum()
relative_hist = hist / cumsum[-1]
cumsum_relative_hist = cumsum / cumsum[-1]
column_data_list = list(zip(
class_name,
class_value,
hist,
cumsum,
relative_hist,
cumsum_relative_hist,
))
df_buf = pd.DataFrame(column_data_list,
columns = ['階級', '階級値', '度数', '累積和', '相対度数', '累積相対度数'])
df_buf.index = np.arange(1, len(df_buf) + 1)
df_buf.to_csv(FILE_NAME + '.csv', encoding = 'utf_8_sig')
extract_hist_data_func(data1_np, my_class_size, my_min, my_max, 'データ1')
extract_hist_data_func(data2_np, my_class_size, my_min, my_max, 'データ2')
以上
<広告>
リンク
リンク