'21/06/12更新:整数の場合に加えて、小数点の場合の例も追記しました。
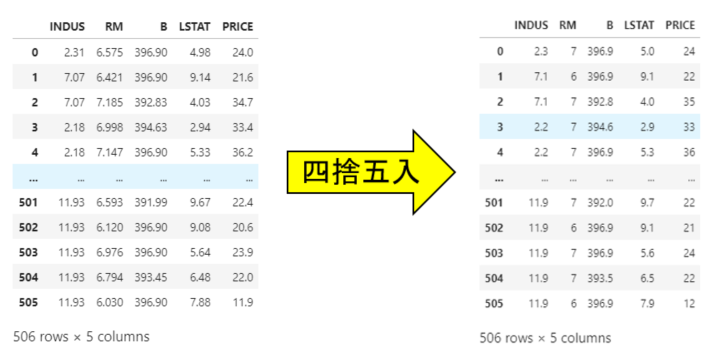
本記事では、pandas(パンダス)データフレーム形式の列データに対して、四捨五入する雛形コードを載せました。下図はその例で、列名「RM」と「PRICE」は整数に、それ以外の列は小数点第一までの値に変換しています。
■本プログラム
import pandas as pd
from decimal import Decimal, ROUND_HALF_UP
import matplotlib.pyplot as plt
file_path = 'test_data.csv'
df = pd.read_csv(file_path)
df
df2 = df.copy()
int_column_list = ['RM', 'PRICE']
for my_col in df.columns:
if my_col in int_column_list:
df2[my_col] = df2[my_col].map(lambda x: int(Decimal(str(x))
.quantize(Decimal('0'), rounding=ROUND_HALF_UP)))
else:
df2[my_col] = df2[my_col].map(lambda x: float(Decimal(str(x))
.quantize(Decimal('0.1'), rounding=ROUND_HALF_UP)))
df2
df2.dtypes
df3 = df2.drop_duplicates()
df3
df3.describe().T
df3.hist(bins=10)
plt.tight_layout()
df3.to_csv('new_' + file_path, index=False)
以上
<広告>
リンク